In the previous part of expression evaluator series, we completed a simple compiler for arithmetic expressions. Now let's add support for variables and improve the code.
Lexer
The first improvement is separating lexer from parser. In the previous version, splitting the expression into tokens was intermixed with token processing. Now, there is a separate function, NextToken, which retrieves the next token. A token may be:
- one of the following operators:
+ - * / = ( ); - a floating-point number;
- a name of variable.
How can you return all these kind of data types from NextToken? The function returns a char, which can be an operator or two special values (TOKEN_NUM and TOKEN_VAR). In the latter case, the calling function should look for the value in _number and _var variables.
Variables
The names and addresses of variables are stored in a hash table. A simple fixed-size (1024 elements) table and Bernstein hash function were used. Both provide good performance for this task.
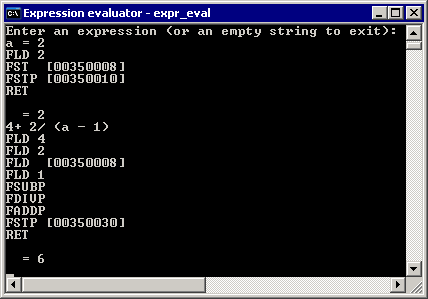
The code to process variables is now very simple. When we encounter a variable name, we check if it is an assignment or usage of previously assigned variable. If the variable is assigned, we emit the code to calculate the expression and store the result in memory. If the value of variable is used in the expression, we just load it from memory:
if(_cur_token == TOKEN_VAR) {
EVAL_CHAR* var_name = _op_start;
if( NextToken() == '=') {
double** stored_to = _var;
NextToken();
ParseSummands();
*stored_to = _code.EmitStoreNumber(ExprCode::P_LEAVE);
} else {
if(NULL == *_var) {
_op_start = var_name;
ReportError(EEE_UNDEF_VAR);
}
_code.EmitLoadVariable(*_var);
}
if(negative)
_code.EmitOperation(OP_CHANGE_SIGN);
}
The evaluator accepts C-style assignments like a = b = 2 or 3 + b = 2 (which means b = 2 and print 3 + b). We could implement Basic-style assignment, which allows assignment only to one variable in an expression, but this would require more complex code. We would have to push token back if the variable is the first token, but there is no assignment (e.g., a + 5). So, simpler C-style assignments were chosen.
As an exercise, you can implement pre-defined variables. For example, add pi variable for "π" number.
Conclusion
This code illustrates some techniques widely used in compilers. Most translators (including commercial C++ compilers) store variables in hash tables and separate lexer from parser. By studying this toy example, you can learn something about "real" compilers.
Download the expression evaluator, 43 KB
The previous part: Reverse Polish notation

16 comments
I've thoroughly enjoyed the education on machine code, which I'm applying to AIMGP.
And what is AIMGP?
It's an AI search algorithm where you generate machine code "organisms", test their fitness through execution of the raw machine code(on a set of test data), then perform crossover/mutation etc on the fitter organisms.
One of the more complex parts is learning machine code and generating it on the fly at run time.
A parser/lexer/tree generator written with the goal to be better than all yacc-based-and-like tools, written in Java but with the C target possible. BCD license.
http://www.antlr.org/
I haven't tried it. The C runtime has around 10000 lines of C (!) which I consider a little too much for something small. But maybe it's good for experimenting or doing something big.
p.s.
I love Red Dragon book (it is one of my fav. computer books) and i don't think that it is so "boring". I highly recomend it even as a starter.
Thank you, Petya! Do you think that implementing FCOMP could be easy? I mean for introducing > or < or ==, and to result 0 for false and 1 for true.
Thanks again!
Keny, your request sounds like you've got a homework assignment and now you expect somebody to do it for you.
IMHO, Keny asked an interesting question. The obvious solution is:
However, FSTSW is slow (see Agner Fog's manuals). A better solution uses FCOMIP and FCMOVcc instructions (available on Pentium Pro and higher):
It's both shorter (less code bytes) and faster.
I understood the question as a request for the expression evaluator which evaluates relational operators.
Thank you for this very good article series.
I have a questions considering the STRINGS or ARRAYS, because you have shown how to deal with numbers INTEGERS and DOUBLES, but ARRAYS of any type are also interesting.
How to allocate a large STRING or any ARRAY type variable in .data segment?
Should I allocate more pages from memory to hold this?
Can I dynamically allocate additional memory if needed during run-time?
Thank you very much for your answers!
Regards,
Darko
My question was connected to my current work.
I am building a scripting engine and execution of native code from memory buffer sounds very good, considering the speed.
It looks like that Google Chrome V8 JavaScript engine is built on this idea.
So, that is what I was wondering while reading your articles.
Can this be applied to the scripting subsystem?
It looks like it can, and that it should be done in this manner.
Thank you again.
Regards,
Darko
Darko, sorry, I misunderstood your question. You can define operations on strings and arrays in the expression evaluator. For example, you can write functions for allocating, concatenating, and slicing the strings. The expression compiler will generate calls to these functions. String literals can be stored in a preallocated array, and string variables can be allocated at runtime.
In a dynamically typed scripting language, you will also have to check types of the variables, generate function prologues and epilogues, allocate local variables on stack, etc. It's more complex than a p-code virtual machine, but IMHO, it's possible. Few years ago, I wanted to write a simple version of such compiler myself.
Thank you, Peter, for your answer.
Regards,
Darko