The basic algorithm for spell checking is simple: for each word in the text, check if it's in your dictionary. If it is not, report a misspelling. The dictionary is usually implemented with a hash table. Handling affixes and capital letters adds some complexity, but the program is still straightforward.
Suggesting the correct word is harder. The usual approach is to check all variations of the word obtained by inserting a letter, replacing one letter with another, skipping a letter, or transposing adjacent letters. For the misspelled word "teh" they will be:
replacing: inserting: skipping: transposing: aeh tah tea ateh taeh teah teha eh eth beh tbh teb bteh tbeh tebh tehb th the ceh tch tec cteh tceh tech tehc te ... ... zeh tzh tez zteh tzeh tezh tehz
The program looks up for each variation in the dictionary, and reports the ones that are found (in this case, tea, tech, eh, and the). The most probable spelling suggestions are then shown to user. This approach is used in ispell and the spelling corrector in Python.
Aspell implements a more complicated scheme using pre-compiled information about similarly sounding words. Other ideas for spelling correction are mentioned in the survey by Roger Mitton.
This article outlines a new solution to the problem based on ternary DAGs.
Ternary search tries
In his book "Algorithms in C", Robert Sedgewick describes a data structure that is suitable for finding similar words. It's called ternary search trie (TST).
Each node of the tree contains three links: the middle one leads to the tree for the next character; the left and right links lead to the nodes of the characters that are smaller and larger than the current one. Each level of the TST is essentially a BST (binary search tree) for searching the character in current position. When the character is found, the program follows its middle link, which leads to the tree of all words starting with the already scanned characters.
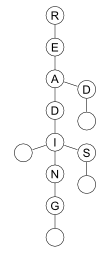
The figure shows a TST for the words red, read, reading, and reads. The null links are not shown. Because one word may be a prefix of another (e.g., read and reading), you need a special node to denote the end of the word. A node with null character conveniently fits this purpose (shown as an empty circle on the figure). The word characters are stored in nodes, so there is no need to keep the strings in memory, as with a hash table.
You can find more explanations on TSTs in the book by Sedgewick and his article in Dr. Dobbs (co-authored with Jon Bentley).
When the dictionary is stored as a TST, you can traverse the adjacent nodes and quickly find spelling suggestions for a given word. Only the words that are in TST are checked. For example, when looking for suggestions to "readimg", you don't need to check all these readiAg, readiBg, readiCg, etc. Only the beginnings of existing words (readiLy, readiEr, readiNess, readiNg, etc.) are checked.
Stemming
It would be interesting to try TST for spelling correction, but it's just too large: a medium-sized English dictionary (100'000 words) requires 320'000 nodes, which is around 5 MB.
Many nodes are taken by affixes: -s, -ed, -ing, un-, etc. The spellcheckers based on hash tables usually strip affixes before searching for a word, so that the hash table contains only root words.
Affix stripping is relatively easy in English, because the language uses inflection limitedly. Other languages (e.g., German, Russian, and Finnish) have more cases and declensions: see analytic language and stemming algorithms.
Designing a stemming engine that can be customized for any language is a challenging task. Ispell follows this path; you can find the inflection rules of different languages in .aff files of Ispell dictionaries.
| Language | Number of rules |
|---|---|
| Estonian | 9249 |
| Finnish (medium-sized) | 8861 |
| Polish | 5454 |
| Spanish | 3274 |
| Czech | 2544 |
| Russian | 1077 |
| Danish | 380 |
| German | 361 |
| Brazilian Portuguese | 271 |
| Italian | 210 |
| Dutch | 116 |
| English | 45 |
More rules do not necessarily mean a more complex morphology because some dictionary authors keep inflected variants in a word list, while others add more affixes for them.
Ternary DAGs
When using TST, we can choose another approach. Note that TST "compresses" the equal prefixes, e.g. on the figure above, read, reading, and reads use the same nodes for the first four characters. What if we try to compress the suffixes, too? The resulting data structure will have only 55'000 nodes instead of 320'000. Let's call it a ternary DAG (a ternary directed acyclic graph).
Miyamoto et al used this data structure for pattern matching, but it's not limited to storing suffixes of a word. An arbitrary set of words can be stored in the DAG:
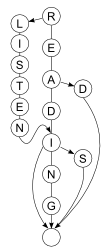
The DAG contains the words red, read, reading, reads, and listen, listening, listens. The middle links of N in listen and D in read lead to the same subgraph containing the suffixes -ing, -s, and a zero-length suffix.
Building a ternary DAG
The DAG can be built from a TST. Let's make a hash table of the TST subtrees (a node and all its children are hashed). When identical subtrees are found, replace all links to them with a link to a single subtree.
By using this procedure, you can automatically find common endings. Affix stripping is not necessary, which has multiple advantages:
- Spelling suggestion search in TST is simplified when all inflected forms are stored in the dictionary.
- The program can find more common endings than a human who makes an affix list. The affix list for English usually contains -ed, -ing, and -s. The program will also find -ment in agreement and increment, -logist in biologist and psychologist, etc. It can find "suffixes" that do not make sense from linguistic viewpoint, e.g., -ead in head and read, but it's not a problem for spellchecking.
The program can find not only single common endings, but also subtrees including multiple endings. On the figure above, there is a subtree including -ing, -s, and zero-length suffix.
The found subtree may be a part of another subtree. Given the words lock, locking, head, heads, headed, heading, and news, the program can compress TST to the following DAG:
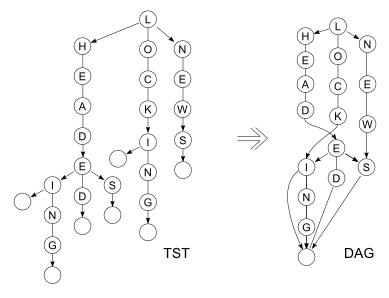
As mentioned above, each level of the TST is a BST. A word list is usually sorted alphabetically, so the BSTs are unbalanced. You can use a usual balancing algorithm to fix this.
The attached program (create_dictionary.c) implements these techniques.
Searching
Searching in a ternary DAG is not different from searching in a TST. You can use the recursive algorithm by Sedgewick and Bentley for exact matching.
A fuzzy matching algorithm for DAG examines adjacent nodes to find a spelling suggestion. Common error patterns (inserting a letter, deleting a letter, etc.) can be expressed elegantly using recursion:
// Correct double letters (including multiple errors in one word, e.g. Misisipi)
static void match_doubles(ST_FILE_NODE* node, const char* word, char* result) {
while(node != NULL) {
if(*word < node->ch)
node = node->left;
else if(*word > node->ch)
node = node->right;
else {
*result = *word;
if(*result == '\0') {
// Found the word
report_suggestion();
return;
}
if(*(word + 1) == *word) {
// When found two equal letters, try to find a single letter
match_doubles(node->middle, word + 2, result + 1);
} else {
// Otherwise, try to find two equal letters here
match_doubles(node->middle, word, result + 1);
}
// Also find the exact match
node = node->middle;
word++;
result++;
}
}
}
The attached spelling corrector (spellchecker.c) handles a single missing letter, an extra letter, a wrong letter, transposed letters, and a missing space.
Performance comparison
The attached benchmark contains a hash table spelling corrector (benchmark.c), which is similar to the one found in Ispell. It generates all possible variants of the misspelled word and tries to find them in the hash table.
The tests were run on a Pentium M processor; execution time was measured in ticks using RDTSC instruction. The dictionary was the medium-sized word list from SCOWL (100'000 English words).
| Algorithm | Spell checking time | Spelling correction time | Size, MB | ||
|---|---|---|---|---|---|
| MSVC | GCC | MSVC | GCC | ||
| hash table | 900 | 1400 | 125'700 | 167'600 | 2.2 |
| ternary DAG | 1700 | 1700 | 81'400 | 111'200 | 0.4 |
Results:
- The hash table implementation is faster for spellchecking. A balanced tree is usually slower than a hash table for searching because of more memory accesses, so this was expected.
- The ternary DAG implementation is faster for spelling correction.
- The ternary DAG takes much less memory than the hash table.
No affix stripping scheme is used in the benchmark (all inflected forms are stored in the hash table). In a real-world spell checker, the hash table would contain only the root words, so it will be smaller, but also slower, which means that the ternary DAG result is really not so bad.
Instead of keeping a word in the hash table, you can store one bit that determines if the word is correct, as described in Programming Pearls book and Bloom Filters blog post. In this case, the size of hash table can be even less than the size of ternary DAG, however, an incorrect word will be reported as correct if their hash values are the same.
Using the code
Run create_dictionary program to generate the dictionary. Include spellchecker.c and spellchecker.h in your project. The following functions are declared in the header file:
// Open a dictionary, returns NULL in case of error
ST_FILE_NODE * ST_open_dict (const char * filename);
// Returns a non-zero value if the word is present in the dictionary
int ST_find_exact (ST_FILE_NODE * dict, const char * word);
// Enumerate spelling suggestions (fuzzy matches)
void ST_enum_suggestions (ST_FILE_NODE * dict, const char * word,
void (* enumproc)(const char*, void*), void * param);
// Close the dictionary
void ST_close_dict (ST_FILE_NODE * dict);
First, you open the dictionary, and then call ST_find_exact for each word of the text. Splitting the text into words is your program's responsibility. If user wants to see the spelling suggestions, call ST_enum_suggestions to find them. Finally, close the dictionary.
The spellchecker_test.c demo program checks spelling of the text in console window.
Future work and ideas
- Improving the suggestion engine. The quality of spelling suggestions is far from that of Microsoft Word or Aspell. The program suggests only the words that are an edit distance of 1 from the misspelled word. A better spelling corrector would also check edit distance 2. The suggestions should be sorted from the most probable to the least probable. “Sounds-like” data and a list of common errors can be included in the corrector.
- Inflection rules support. When using create_dictionary program, you should provide a word list with all inflected forms (e.g., address, addresses, address's, addressing, addressed). It's not a problem for English, where the number of forms is relatively small. For synthetic languages, it may be handier to use a word list with roots only and a separate list of inflection rules, like Ispell does.
- Adding words at runtime. The current program compiles the dictionary into ternary DAG format, and then reads from it. Online construction of the ternary DAG is possible, but requires keeping more information in memory (a hash table for TST and auxiliary counters in the nodes). In this case, a more complex algorithm for adding words should be implemented to use the existing suffixes in DAG and to keep the BSTs balanced.
Conclusion
Ternary DAG is a compact representation of spell-checking dictionary, which is faster than a hash table for spelling correction, but not for spellchecking. With a ternary DAG, you can avoid affix stripping, which complicates a spell checker.
Download the spelling corrector (530 KB)

6 comments
Hi,
Just wanted to say thank you for the spell checker! This is very thorough and very well written! Not to mention how fast it is!
Peter,
I found your article on codeproject.com and it was so good, it inspired me to get back into C++ programming and write another CodeProject article. It uses a modified version of your ST_enum_suggestions function to generate a list of spelling suggestions that can be marshaled to C#.
Here is the link to my article:
http://www.codeproject.com/Articles/441871/Fast-String-Searching-Using-Cplusplus-STL-Vectors
I have also posted new comments on your article here:
http://www.codeproject.com/Articles/32089/Using-Ternary-DAGs-for-Spelling-Correction
Hello Mister Kankowski,
I have leave a comment on Codeproject:
http://catalog.codeproject.com/Articles/32089/Using-Ternary-DAGs-for-Spelling-Correction?msg=4379177#xx4379177xx
Thank you for the article...
Yours,
Hi,
Great post, thank you very much! This is just awesome!
I have a question: I was reading about balancing Ternary Search Trees with some techniques,
because they can be very skewed for certain sets of words (e.g. if you insert in aphabetical order).
What you think about this?
And, would balancing affect positively also Ternary DAGs?
My Bests
Hi, John,
yes, I balanced the ternary DAGs (see "Building a ternary DAG" section above).
See also a newer article here: http://www.strchr.com/dawg_predictive